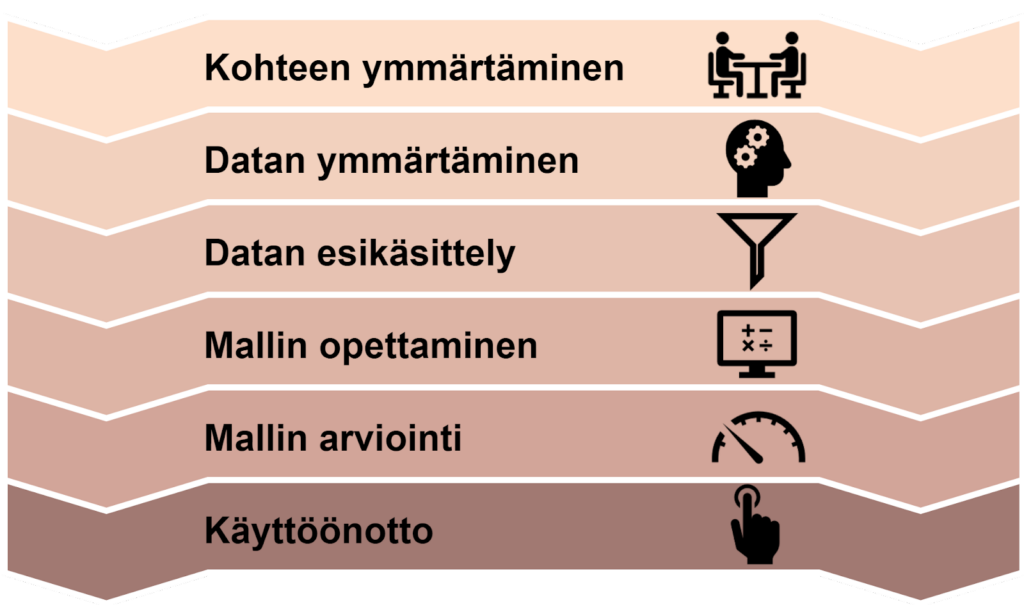
Hahmottelimme Fonzitille tekoälyprojektin mallin. Monissa lähteissä tekoälyprojekti esitetään syklisenä kehänä, jossa lopusta palataan takaisin alkuun. Esikuvana on luultavasti ollut 1990-luvun lopulla luotu tiedonlouhinnan prosessi nimeltä CRISP-DM (Cross-industry standard process for data mining). Tämä ei kuitenkaan sovellu projektimalliksi, koska projektilla on alku, loppu ja aikataulu.
Fonzitin tekoälyprojekti alkaa ymmärtämisestä ja päättyy käyttöönottoon. Vaiheiden välillä on iteraatiota, mutta pidimme kaaviokuvan selkeänä emmekä piirtäneet kaksisuuntaisia nuolia kaikesta kaikkeen.
Jotta kuivan aiheen parissa viihtyisi jutun loppuun saakka, pyysimme Satiiri Oy:n tekoälykonsulttia avuksi tarkastelemaan projektimallia. Onneksemme hän ei työskentele Fonzitissa.
Kohteen ymmärtäminen: minkä ongelman haluamme ratkaista?
Konsultti: Päivää, olen tekoälyasiantuntija. Millaisia ongelmia voisimme yhdessä ratkaista tekoälyllä? Asiakas: Meillä on tällainen kehittämisprojekti alkamassa. Siinä on tavoitteena lisätä myyntiä, leikata tuotantokustannuksia sekä parantaa henkilöstön tyytyväisyyttä. K: Kuulostaa kiinnostavalta. Siinä olisi varmasti tekoälylle tarvetta, eikö niin. A: Minkälaista tekoälyä suosittelet tähän tarkoitukseen? K: Nythän on uusinta uutta tämä GPT-3, uskoisin että teidänkin yrityksestä löytyy tarpeita sille. A: Paljonko se maksaa? K: Tuleehan siitä kustannuksia, mutta tärkeämpää on nähdä mahdollisuudet, joita tekoäly tarjoaa liiketoiminnalle.
Emme voi ratkaista tehtävää, ennen kuin ymmärrämme, mitä olemme ratkaisemassa. Monesti tämä aloitusvaihe nimetään bisneksen ymmärtämiseksi, mutta kaikki sovelluskohteet eivät ole bisnestä. Suomessa monet datahankkeet tehdään julkisella sektorilla, missä ei tehdä bisnestä mutta on paljon dataa.
Ensimmäinen ja tärkein kysymys on: tarvitaanko tähän tekoälyä ensinkään? Tekoäly ei ole itsetarkoitus, vaan joskus ongelma voidaan ratkaista ja tavoite saavuttaa yksinkertaisemmillakin konsteilla.
Tekoälyprojektissa kohteen ymmärtäminen koskee erityisesti sovellusaluetta, josta data tulee. Haluammeko ennustaa tulevien kuukausien myyntiä, valvoa tuotantolinjan laatua konenäön avulla vai kenties käsitellä asiakaspalautetta tekstianalytiikan keinoin? Vaihteleeko myynti sesongin mukaan, minkälaisia laatupoikkeamia tuotantolinjalta haetaan tai mitä asiakaspalautteille tehdään analysoinnin jälkeen? Kun tekoälyasiantuntija ymmärtää vastaukset näihin kysymyksiin, voimme ruveta laatimaan projektisuunnitelmaa.
Datan ymmärtäminen: millaista dataa tarvitsemme?
K: Onko teillä dataa? A: Meillä on paljon dataa. Osa siitä on SQL-kannoissa ja data warehousessa, mutta ne on niin vaikeita käyttää että porukka on tallentanut paljon dataa ihan vaan verkkolevylle Excel-tiedostoihin. Myyntidataahan me on kerätty 20 vuotta ja asiakaspalautetta vähintään saman verran. Tuotantokoneilta on sitten oma datansa, jota on tallessa laitevalmistajan omassa formaatissa. Viime vuonna otettiin käyttöön uusi tuotannonohjausjärjestelmä, eli sinnekin on ruvennut dataa kertymään. Asiakastiedot on alun perin olleet paperilla mapeissa, joista ne on sitten skannattu pdf-tiedostoihin. Sitten on vielä tallennettuja puhelinkeskusteluja asiakaspalvelusta. K: Ohhoh, onhan sitä. Pannaanpa tekoäly selvittämään, mitä data sisältää. Lisäksi meillä on valmiudet yhdistää teidän dataan säätietoja, pörssikursseja ja auringonpilkkuja.
Valitettavasti tekoäly ei ole laatikko, johon voi kaataa dataa ja ravistaa. Usein dataa on kertynyt kosolti, mutta kukaan ei ole perillä, missä sitä on ja kuinka sitä voisi käyttää. Kun edellisessä vaiheessa suunniteltiin tavoitteita datalähtöisesti, nyt datan ymmärtämisvaiheessa mietitään, millaisella datalla tavoitteet saavutetaan.
Tuotantolinjan mittausdatalla voidaan luoda koneoppimismalli, joka havaitsee poikkeamat tuotannossa. Myynnin ennustamiseksi täytyy miettiä, minkälaista inputia kannattaisi käyttää. Algoritmi voidaan ohjelmoida luokittelemaan asiakkaat, minkä jälkeen pohditaan, miten syntyneitä asiakassegmenttejä hyödynnetään markkinoinnissa. Tämän vaiheen tulosten jälkeen loppu on toteuttamista.
Datan esikäsittely: miten datasta tuee käyttökelpoista?
K: Lähdetäänpä tekemään koneoppimismallia teidän datalla. Tarvitsisin tunnukset järjestelmään, josta sitä löytyy. A: Annan sinulle yhteystiedot meidän pilvipalveluntarjoajalle, voit ottaa yhteyttä sinne niin saat tunnukset. K: Meillä oli myös puhetta eri datalähteiden yhdistelystä. A: Se onkin vähän hankalampaa, kun tuotantodata on kerätty sekuntitasolla ja myyntitiedot kerran kuussa. Lisäksi se kaveri, joka vastasi asiakastietojen ylläpidosta, lähti firmasta viime vuonna.
Jos data olisi valmiiksi oikeassa muodossa ja helposti saatavilla, tekoälyprojekti olisi luultavasti jo valmis. Mutta koska näin ei ole, tarvitaan esikäsittelyä. Nyt haromme hiuksia ja joudumme ehkä tekemään kompromisseja, jotta dataa saadaan käyttöön. Esikäsittelyvaiheessa yhdistetään ne sekunti- ja kuukausitason tiedot jollakin tavalla, rikastetaan alueellisia myyntilukuja alueen asukastiheydellä, muunnetaan eri maista tulevat päivämääräformaatit yhteneviksi ja siivotaan puhelinnumerot pois sähköpostikentästä. Eipä ihme, että esikäsittelyn sanotaan olevan kaikkein työläin vaihe koko projektissa.
Mallin opettaminen: miten tekoäly oppii sitä mitä halutaan?
K: Olemme nyt saaneet algoritmin koodattua ja voimme siirtyä opettamaan mallia. Käytämme tähän tarkoitukseen random forest -regressiomallia opetettuna gradient boosting -algoritmilla. A: On kuitenkin syytä muistaa, että tämä ei ole mikään low-hanging fruit vaan tärkeintä on tuottaa robustia impaktia bisnekselle. K: Ilman muuta. Dataa on niin paljon, että löydämme varmasti oikeat asiat. Tarvittaessa lisätään laskentakapasiteettia pilvipalvelussa.
Harva datatieteilijä koodaa nykyään itse algoritminsa. Valmiit kirjastot ja laskentapalvelut sisältävät lähes kaiken tarvittavan, jolloin itse algoritmi voi olla vain muutama rivi koodia tai pari lohkoa tekoälytyökalussa. Asiantuntijan täytyy kuitenkin tuntea työkalunsa ja osata kertoa, mitä laatikon sisällä tapahtuu ja miksi tulokset ovat sellaisia kuin ovat. Liiketoimintajohtajaa ei yleensä kiinnosta, mikä on päätöspuun syvyyden maksimiarvo tai monikokertaista ristiinvalidointia käytetään, vaan hän haluaa tietää, mitä resursseja mallin opettamiseen tarvitaan ja miten mallin ominaisuudet auttavat saavuttamaan tavoitteet.
Mallin arviointi: mitkä ovat oikeat mittarit ja kriteerit?
K: Lupaavia tuloksia opetusdatan mallinnuksesta. Väärien negatiivisten osuus on lähes nolla. A: Mitä se tarkoittaa? K: Sitä että konenäkösovellus pystyy tunnistamaan jopa kaikki virheelliset tuotteet. A: Entä jos se heittää varmuuden vuoksi virheettömiäkin tuotteita hylkyyn? K: Ei hätää, laitetaan neuraaliverkkoon lisää parametreja niin saadaan sataprosenttiset tulokset.
Väärien negatiivisten osuutta ei kannata vääntää väkisin nollaksi, ei ainakaan lisäämällä malliin parametreja.
Mallin arviointikriteerin valinta vilisee tieteellisiä termejä kuten precision, recall, MSE, R2, joita ei onneksi tarvitse muistaa ulkoa muualla kuin koneoppimiskurssin tentissä. Tärkeää on kuitenkin valita se mittari, joka tukee valittua tavoitetta. Esim. ennusteen hyvyyttä arvioitaessa neliöllinen keskivirhe (MSE) on usein hyvä mittari, joka sakottaa suurista virheistä toiseen potenssiin. Jos laadunvalvonnassa on erityisen tärkeää löytää kaikki vialliset tuotteet, sopiva kriteeri on recall, joka pyrkii löytämään kaikki vialliset silläkin uhalla että samalla hylätään virheettömiä tuotteita – aivan kuten satiirikonsultti yllä lupaili.
Käyttöönotto: miten malli pysyy kunnossa?
K: Tekoälymalli pyörii nyt tuolla serverillä. Tässä on käyntikorttini, soittele jos tulee ongelmia. A: Kiitos yhteistyöstä, eiköhän me pärjätä itse tästä eteenpäin.
Tekoälyprojekti päättyy mallin käyttöönottoon, mutta seuranta ja ylläpito eivät pääty. Vaikka tekoälystä parhaassa tapauksessa saadaan tavoiteltuja hyötyjä heti alussa, asenna ja unohda -menetelmä on harvoin toimiva ylläpitotapa. Mallinnettu kohde muuttuu, uutta dataa kertyy ja malli vaatii päivitystä. Jos tilanne muuttuu hitaasti, vaikkapa henkilöstön palkkataso nousee, tekoälymalli oppii uutta vähitellen, kun sitä päivitetään uudella datalla. On mietittävä, kannattaako vanhaa dataa poistaa sitä mukaa kuin uutta kertyy, vai päivitetäänkö mallia alati kasvavalla datamäärällä. Jos taas kohdetta kohtaa äkillinen muutos kuten uusi toimipaikka tai idänkaupan tyrehtyminen, tekoäly ei pysty sitä ennustamaan, vaan täytyy kerätä uutta dataa uudesta tilanteesta.
Lue myös
25.04.2025
Asiakasdata jalostuu AI:n avulla
Vuodesta 2010 toiminut kotimainen NBO tarjoaa B2B-myyntipalveluja organisaatioille, joiden kohderyhmänä on Suomen 2000 suurinta yritystä. NBO dokumentoi, analysoi ja raportoi myyntikeskuskustelujen perusteella kerättyä
27.02.2025
Tekoäly etädiagnostiikan tukena
Klinik Healthcare Solutions on suomalainen terveysteknologiayritys, jonka tarjoamat sovellukset pyrkivät helpottamaan terveydenhuollon painetta ja nopeuttamaan siihen liittyviä prosesseja tekoälyavusteisesti. Klinikin perusti ryhmä lääkäreitä ja sovelluskehittäjiä,
22.10.2024
Tekoälyllä voi myös rakenteellistaa dataa
Innostus generatiivisten kielimallien kanssa leikkimiseen valtasi maailman reilu vuosi sitten, kun ChatGPT julkaistiin. Sanon leikkimiseen, koska suuri osa käytöstä on ollut huumorilla höystettyä kokeilua.