Innostus generatiivisten kielimallien kanssa leikkimiseen valtasi maailman reilu vuosi sitten, kun ChatGPT julkaistiin. Sanon leikkimiseen, koska suuri osa käytöstä on ollut huumorilla höystettyä kokeilua. Toki myös liiketoimintaa generatiivisilla malleilla pyritään kehittämään, ja pyrkimys jatkuu. Tässä kirjoituksessa esittelen yhden lupaavan tavan käyttää GPT-tyyppistä mallia datan jalostamiseen. Käytän sanaa tekoäly merkityksessä generatiivinen tekoälymalli, koska niin on nykyään tapana varsinkin puhekielessä.
Lähes ainoa käyttöliittymä generatiiviseen tekoälyyn on kehote (prompt). Tekoälylle kirjoitetaan selväkielinen teksti, jossa sitä kehotetaan generoimaan halutunlainen teksti tai kuva. Juuri tämä luonnollisen kielen käyttö ilman matematiikkaa tai tiedettä on tuonut tekoälyn kenen tahansa ulottuville. Kehotesuunnittelusta (prompt engineering) kirjoitetaan kokonaisia kirjoja ja pidetään kursseja.
Vaikka tekoälyllä on taipumus jaaritella tai peräti hallusinoida, sopivalla kehotteella sitä voi kahlita. Pyysin GPT-4-mallia etsimään avainsanat antamistani tekstidokumenteista ja palauttamaan vastauksen tarkan rakenteen mukaan. Vastaavalla tavalla voisi tekstistä hakea ja rakenteellistaa myös numerotietoja.
Valitsin esimerkkiteksteiksi kansanedustajien puheenvuoroja, jotka ovat julkisesti saatavilla eduskunnan avoimen datan palvelusta. Puhuminen on kansanedustajien työtä, eivätkä he tunnetusti aina pyri tiiviiseen ilmaisuun. Puheenvuoroja kertyy vaalikaudessa kymmeniätuhansia. Jos tekoäly pystyisi tiivistämään puheenvuoron olennaiset asiat, päästäisiin asian ytimeen ja jatkamaan muilla datatieteen menetelmillä.
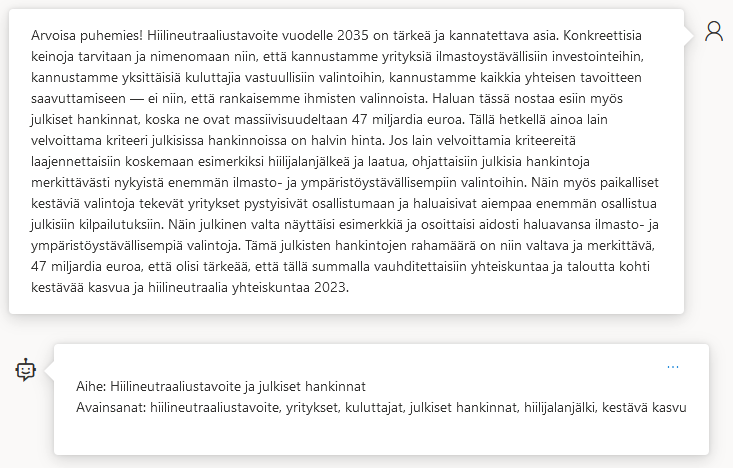
Yllä olevassa esimerkissä on kokoomuksen Ruut Sjöblomin lyhyehkö puheenvuoro täysistunnossa 22.2.2023 sekä GPT-4:n siitä tiivistämät aihe ja avainsanat. Tekoälyn aikaansaannos on mielestäni kiitettävä. Aihe Hiilineutraaliustavoite ja julkiset hankinnat vastaa hyvin puheenvuoron sisältöä, ja avainsanat ovat kuin ovatkin keskeisiä eivätkä turhia täytesanoja. Avainsanoja ei ole valittu lukumäärän perusteella: esim. kestävä kasvu esiintyy tekstissä vain kerran mutta on silti keskeinen käsite, kun taas sana euro toistuu kaksi kertaa mutta ei ole päätynyt avainsanaksi. Kannattaa huomata myös, että tekoäly osaa perusmuotoistaa eli lemmatisoida: esim. hiilijalanjälki esiintyy tekstissä vain taivutetussa muodossa, mutta avainsanalistassa se on perusmuodossaan. Tämä on tärkeää jatkokäsittelyn kannalta.
Seuraavaksi tiivistin samalla menetelmällä jokusen puheenvuoron lisää ja kokosin tulokset taulukkoon. Taulukko sisältää vain muutaman esimerkin, mutta riittävällä laskentakapasiteetilla voisi käsitellä vaikka kaikki puheenvuorot. Taulukkoa voi silmäillä, saahan siitä nopeasti käsityksen, mitä sen päivän puheenvuorot käsittelivät. Tärkeämpi käyttötapa on kuitenkin datatiede. Avainsanat ovat nyt rakenteisessa muodossa, jota voi käyttää monenlaiseen analytiikkaan ja koneoppimiseen. Puheenvuorojen luokittelu, avainsanojen jakauma, uusien aiheiden nouseminen esiin ja eduskuntaryhmien väliset erot ovat kiinnostavia esimerkkejä.
Käytin esimerkkinä eduskunnan puheenvuoroja, koska ne ovat helposti saatavilla ja niitä on paljon. Vastaavia tekstiaineistoja on kaikkialla. Samalla tekniikalla voi kaivaa rakenteista dataa johtokunnan kokouspöytäkirjoista, myyntitapaamisten muistioista, oikeuden päätöksistä tai pörssitiedotteista. Tekoäly löytää myös numerotietoja tai nimiä, jos sellaisia tekstissä vilahtelee. Rakenteisen datan jatkojalostustapoja on paljon, mm. visualisointi, analytiikka ja monet ”perinteisen” koneoppimisen menetelmät.
Lue myös
25.04.2026
Asiakasdata jalostuu AI:n avulla
Vuodesta 2010 toiminut kotimainen NBO tarjoaa B2B-myyntipalveluja organisaatioille, joiden kohderyhmänä on Suomen 2000 suurinta yritystä. NBO dokumentoi, analysoi ja raportoi myyntikeskuskustelujen perusteella kerättyä… Read More
27.02.2026
Tekoäly etädiagnostiikan tukena
Klinik Healthcare Solutions on suomalainen terveysteknologiayritys, jonka tarjoamat sovellukset pyrkivät helpottamaan terveydenhuollon painetta ja nopeuttamaan siihen liittyviä prosesseja tekoälyavusteisesti. Klinikin perusti ryhmä lääkäreitä… Read More
31.08.2025
Tekoäly liikuttaa koneita
Autonomiset koneet on Fonzitin käyttämässä jaottelussa yksi tekoälyn sovelluskohde. Autonomisia koneita ovat esim. autonomiset autot, teollisuusrobotit ja ihmisen kaltaiset robotit eli humanoidirobotit. Joskus… Read More