Ohjaamaton vai ohjattu koneoppiminen

Edellisessä tekstissäni esittelin tekoälyyn liittyviä käsitteitä. Tärkein niistä on koneoppiminen, joka ansaitsee vielä toisenkin kirjoituksen. Tällä kertaa kerron koneoppimismenetelmien jaosta ohjattuun ja ohjaamattomaan oppimiseen.
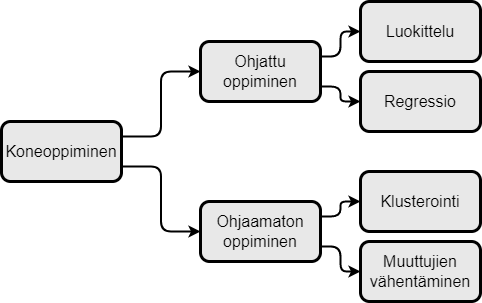
Ohjatussa oppimisessa (supervised learning) tavoitteena on useimmiten ennustaminen: ensin malli opetetaan input-output-datalla, ja opetuksen jälkeen halutaan ennustaa uusille inputeille mahdollisimman oikea output. Opetusdatan täytyy sisältää ”oikea vastaus” eli output-muuttuja, jonka avulla koneoppimismalli oppii matkimaan datan sisältämää input-output-riippuvuutta.
Opetusdatan output-leima on lähes aina ihmisen tekemä. Toisin sanoen koneoppimista varten tarvitaan historiadataa, jossa ihmisen tekemä output on yhdistetty inputeihin. Joskus nämä ovat valmiiksi yhdessä, joskus yhdistäminen on hankalaa ja kallista. Jos kuvantunnistusalgoritmin halutaan oppivan tunnistamaan kissan kuvia, tarvitaan suuri määrä kuvia, joista tiedetään onko kuvassa kissa vai ei. Valmiiksi leimattua kissankuvadataa on julkisesti saatavilla, mutta omaa sovellusta varten yrityksen täytyy itse kerätä datansa. Jos pankki haluaa koneoppimisalgoritmin tekevän lainapäätöksiä, tarvitaan opetusdataksi ihmisen tekemiä päätöksiä.
Output-datan keräämisen vaikeutta helpotetaan joskus ns. puoliohjatulla oppimisella (semi-supervised learning). Siinä yhdistellään sekä ohjatun että ohjaamattoman oppimisen menetelmiä, jolloin output-leimoja tarvitaan vain osaan datasta.
Ohjatussa oppimisessa syntyy joko luokittelumalli tai regressiomalli. Luokittelumallissa output-muuttuja on luokka, kuten edellä mainitut ”kissa vai ei” tai lainapäätös, regressiomallissa taas jatkuva arvo, esim. pörssikurssi. Yksinkertaisin esimerkki regressiomallista on lineaarinen regressio yhdellä input- ja yhdellä output-muuttujalla, siis tuttu suoran sovitus pisteparveen (kuva alla). Se löytyy jokaisesta datankäsittelyohjelmasta parilla hiiren klikkauksella. Vähänkin monimutkaisemmassa mallissa riippuvuus on epälineaarinen ja input-muuttujia on useita, jolloin havainnollistavan kuvan piirtäminen vaikeutuu.
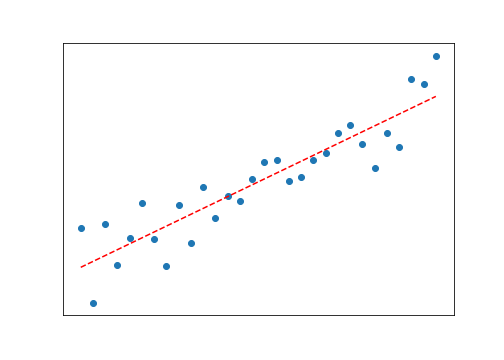
Hetkinen, onko suoran sovitus siis koneoppimista? Kyllä on, koska se perustuu dataan ja tuottaa mallin. Malli on se suora, ja suoran avulla voidaan interpoloida tai ekstrapoloida eli ennustaa, millaisen outputin uusi input-piste tuottaa. Jos datapisteitä sattuisi olemaan vain kaksi, silloin suoran ”sovitus” tarkoittaisi viivan piirtämistä näiden kahden pisteen välille. Kaikki tekoäly ei ole rakettitiedettä. (Eri asia on, kannattaisiko luottaa koneoppimismalliin, joka perustuu kahteen datapisteeseen.)
Ohjaamatonta oppimista (unsupervised learning) voi käyttää silloinkin, kun datassa ei ole tunnettua outputia. Ohjaamattoman oppimisen avulla voidaan ikään kuin tutustua laajaan datamassaan ja tiivistää sen sisältöä. Tuloksena voidaan saada esim. muuttujien vähentäminen, jossa datasta poistetaan samaa asiaa kuvaavia muuttujia (sarakkeita), tai klusterointi, jossa samankaltaiset datapisteet etsiytyvät samaan klusteriin. (Sanalle klusterointi on olemassa myös hyvä suomenkielinen vastine ryvästys, mutta sitä näkee käytettävän kovin harvoin.)
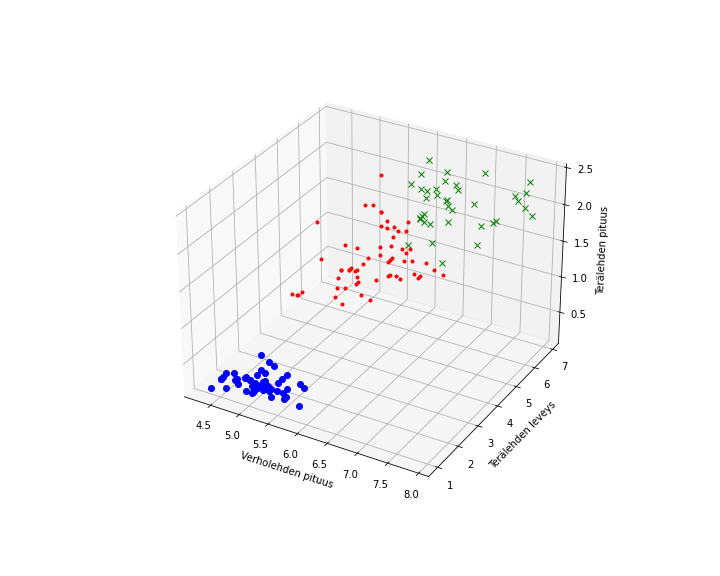
Alla oleva kuva on yksinkertainen esimerkki klusteroinnista kuuluisalla Iris-datajoukolla. Datapisteet esittävät kolmen kurjenmiekat-sukuun kuuluvan kasvilajin yksilöistä mitattuja terälehtien mittoja. Klusterointialgoritmi on jakanut pisteet kolmeen klusteriin, jotka on piirretty kuvaan eri värein. Yksi klusteri erottuu selvästi, kun taas kaksi muuta näyttävät limittyvän tässä kuvassa. Kolmiulotteinen kuva ei kuitenkaan kerro kaikkea, koska mittauksia on neljä ja neljäs ulottuvuus ei mahdu kuvaan. Kun kyse on ohjaamattomasta oppimisesta, emme tiedä ovatko klusterien rajat samat kuin todellisten kurjenmiekkalajien erot – luultavasti eivät ainakaan täsmälleen samat.
Joskus ohjatun ja ohjaamattoman oppimisen rinnalla esitetään myös vahvistusoppiminen (reinforcement learning). Siinäkin malli oppii palautteen perusteella, mutta eri tavalla kuin ohjatussa oppimisessa. Kun pelialgoritmi häviää pelin tai liikkuva robotti törmää esteeseen, tapahtuu vahvistusoppimista.
Yhteenveto: Ohjaamattomaan oppimiseen voit käyttää melkein mitä tahansa dataa, kun taas ohjattuun oppimiseen tarvitset output-leimoja, jotka voivat olla kiven alla. Kaikki kuulostaa helpolta blogitekstissä, mutta käytännön työ on aika paljon mutkikkaampaa. Ota yhteyttä niin jutellaan lisää.
Mikko Laurikkala, AI Lead, Fonzit Oy